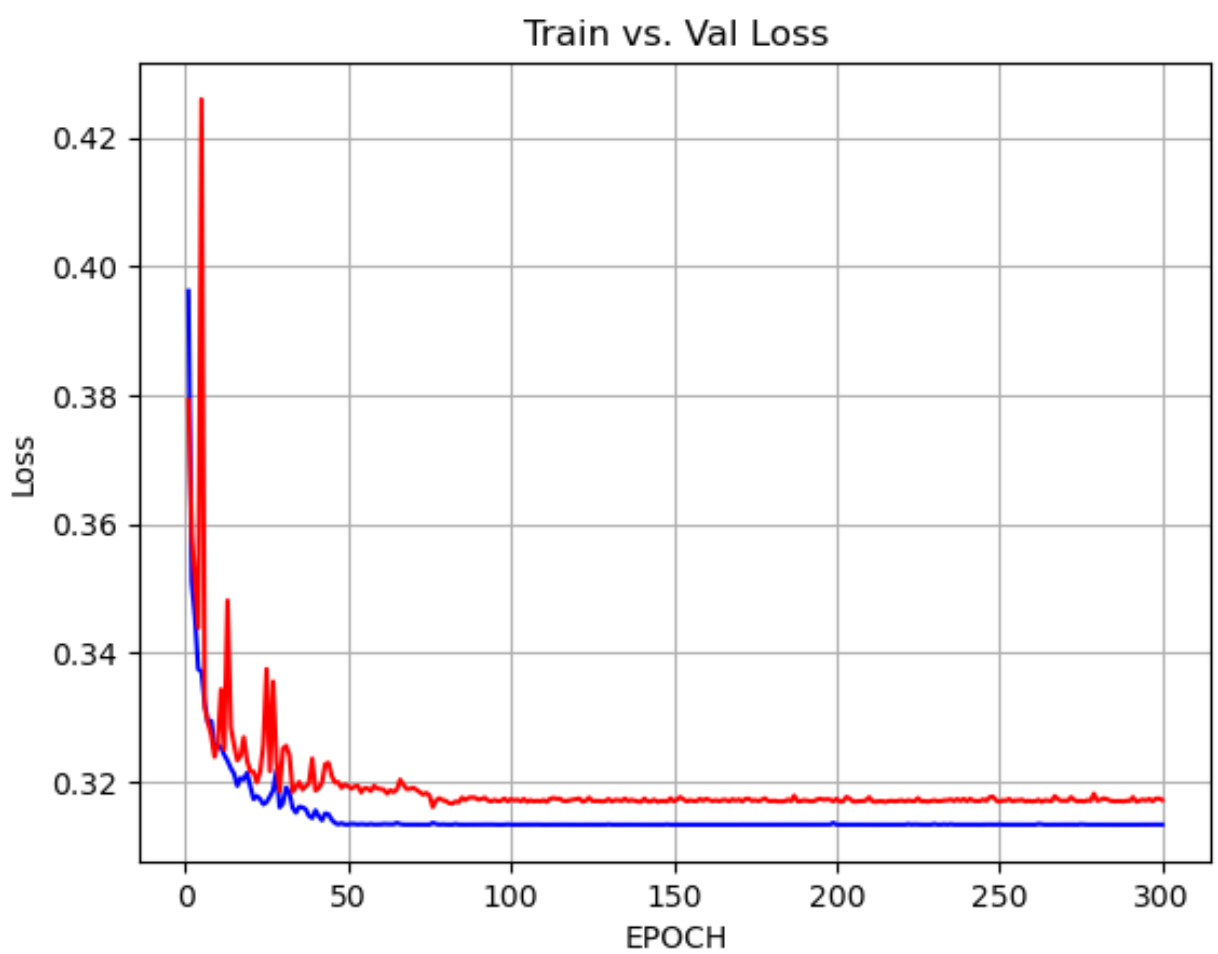
전체 소스 코드
GitHub - 21june/FaceMaskDetection: C# WPF - Face Mask Detection
C# WPF - Face Mask Detection. Contribute to 21june/FaceMaskDetection development by creating an account on GitHub.
github.com
Nuget 패키지
다음과 같이 Nuget 패키지를 등록합니다.
<ItemGroup>
<PackageReference Include="OpenCvSharp4" Version="4.10.0.20241108" />
<PackageReference Include="OpenCvSharp4.Extensions" Version="4.10.0.20241108" />
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.10.0.20241108" />
<PackageReference Include="OpenCvSharp4.Windows" Version="4.10.0.20241108" />
<PackageReference Include="OpenCvSharp4.WpfExtensions" Version="4.10.0.20241108" />
</ItemGroup>UI XAML 파일 (MainWindow.xaml)
UI는 다음과 같은 소스 코드를 따릅니다.
<Window x:Class="MaskDetection.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:MaskDetection"
mc:Ignorable="d"
Title="MainWindow" Height="640" Width="1024">
<Grid>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="0.6*" />
<ColumnDefinition Width="0.4*" />
</Grid.ColumnDefinitions>
<!-- Left (Picture) -->
<Grid Grid.Column="0">
<Image x:Name="image_cam" Stretch="Uniform"/>
</Grid>
<!-- Right (Menu) -->
<Grid Grid.Column="1">
<Grid.RowDefinitions>
<!-- 1. Input-->
<RowDefinition Height="0.3*" />
<!-- 2. Model -->
<RowDefinition Height="0.2*" />
<!-- 3. Face Detection -->
<RowDefinition Height="0.2*" />
<RowDefinition Height="0.3*" />
</Grid.RowDefinitions>
<!-- 1. Input -->
<GroupBox Grid.Row="0" Header="Input" Margin="5" FontSize="15">
<Grid>
<Grid.RowDefinitions>
<!-- Camera -->
<RowDefinition Height="0.5*" />
<!-- Image -->
<RowDefinition Height="1.0*" />
</Grid.RowDefinitions>
<!-- Camera -->
<Grid Grid.Row="0">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="0.3*" />
<ColumnDefinition Width="0.7*" />
</Grid.ColumnDefinitions>
<TextBlock Grid.Column="0" Text="Camera" VerticalAlignment="Center" FontSize="20" />
<Button Grid.Column="1" x:Name="button_cam" Content="Open" Click="ClickEvent" FontSize="20" Margin="10"/>
</Grid>
<!-- Image -->
<Grid Grid.Row="1">
<Grid.RowDefinitions>
<RowDefinition Height="0.5*" />
<RowDefinition Height="0.5*" />
</Grid.RowDefinitions>
<!-- Load Button... -->
<Grid Grid.Row="0">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="0.3*" />
<ColumnDefinition Width="0.7*" />
</Grid.ColumnDefinitions>
<TextBlock Grid.Column="0" Text="Image" VerticalAlignment="Center" FontSize="20"/>
<Button x:Name="button_image" Grid.Column="1" Content="Load" Click="ClickEvent" FontSize="20" Margin="10"/>
</Grid>
<!-- Path Text... -->
<TextBlock x:Name="text_image" Grid.Row="1" TextWrapping="Wrap" VerticalAlignment="Center" Text="No File" FontSize="15"/>
</Grid>
</Grid>
</GroupBox>
<!-- 2. Model -->
<GroupBox Grid.Row="1" Header="Mask Detection" Margin="5" FontSize="15">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="0.5*" />
<RowDefinition Height="0.5*" />
</Grid.RowDefinitions>
<!-- Load -->
<Grid Grid.Row="0">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="0.3*" />
<ColumnDefinition Width="0.7*" />
</Grid.ColumnDefinitions>
<TextBlock Grid.Column="0" Text="File" VerticalAlignment="Center" FontSize="20" />
<Button x:Name="button_model" Grid.Column="1" Content="Load" Click="ClickEvent" FontSize="15" Margin="5"/>
</Grid>
<!-- Path -->
<TextBlock x:Name="text_model" Grid.Row="3" TextWrapping="Wrap" VerticalAlignment="Center" Text="No File" FontSize="15"/>
</Grid>
</GroupBox>
<!-- 3. Face Detection -->
<GroupBox Grid.Row="2" Header="Face Detection" Margin="5" FontSize="15">
<Grid>
<Grid.RowDefinitions>
<RowDefinition Height="0.5*" />
<RowDefinition Height="0.5*" />
</Grid.RowDefinitions>
<!-- Enable -->
<Grid Grid.Row="0">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="0.3*" />
<ColumnDefinition Width="0.7*" />
</Grid.ColumnDefinitions>
<TextBlock Grid.Column="0" Text="Enable" VerticalAlignment="Center" FontSize="20" />
<CheckBox Grid.Column="1" x:Name="check_facedet" Content="Auto Face-Cognition" VerticalAlignment="Center" Margin="10" Click="ClickEvent"/>
</Grid>
<!-- Confidence -->
<Grid Grid.Row="1">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="0.3*" />
<ColumnDefinition Width="0.7*" />
</Grid.ColumnDefinitions>
<TextBlock Grid.Column="0" Text="Confidence" VerticalAlignment="Center" FontSize="20" />
<Slider x:Name="slider_face_conf" Grid.Column="1" Minimum="0" Maximum="100" VerticalAlignment="Center" ValueChanged="SliderEvent" />
</Grid>
</Grid>
</GroupBox>
</Grid>
</Grid>
</Window>

MainWindow.xaml.cs
다음과 같이 변수들을 초기화했으며, OpenCvSharp.Dnn.CvDnn.ReadNetFromOnnx 함수를 통해 이전 포스팅에서 생성한 onnx 파일을 로드해줍니다. modelPath 값의 경우 onnx 파일 경로에 맞게 수정해주셔야 합니다.
public partial class MainWindow : Window
{
VideoCapture m_capture;
Thread t_cap;
bool m_isRunning = false;
bool b_facecog = true;
OpenCvSharp.Dnn.Net net;
OpenCvSharp.Size resz = new OpenCvSharp.Size(224, 224);
// Mean & Standard Deviation
bool b_meanstd = false;
static float[] mean = new float[3] { 0.5703f, 0.4665f, 0.4177f };
static float[] std = new float[3] { 0.2429f, 0.2231f, 0.2191f };
float face_confidence = 0.5f;
public MainWindow()
{
InitializeComponent();
m_capture = new VideoCapture();
// 모델 로드
string mask_model = "resnet18_Mask_12K_None_EPOCH200_LR0.0001.onnx";
net = OpenCvSharp.Dnn.CvDnn.ReadNetFromOnnx(mask_model);
// UI 처리
if (!net.Empty()) text_model.Text = "Model: " + mask_model;
else text_model.Text = "Model: " + "No Model";
slider_face_conf.Value = (int)(face_confidence * 100);
check_facedet.IsChecked = b_facecog = true;
}
...
}
ClickEvent 함수는 각 UI의 클릭 이벤트 시 호출되는 함수입니다.
1. button_cam의 경우 카메라를 연결하고 영상을 가져와 추론 후 결과를 출력하는 과정을 스레드 해제까지 수행합니다.
2. button_image은 파일 열기 다이얼로그를 실행하여 이미지 파일을 선택하고 해당 이미지를 불러와 추론 후 결과를 나타냅니다.
3. button_model은 파일 열기 다이얼로그를 실행하여 모델 파일(*.onnx)을 선택하고 해당 모델을 불러와 추론 시 사용합니다.
4. check_facedet은 체크하면 사람의 얼굴을 찾고 각 얼굴 별 마스크를 착용했는지 확인합니다. 체크 해제 시에는 전체 이미지를 검사합니다.
SliderEvent 함수는 슬라이더의 값 변경 시 호출됩니다. 해당 값을 계산하여 confidence 값에 사용합니다.
// 버튼 클릭 이벤트
private void ClickEvent(object sender, RoutedEventArgs e)
{
if (sender.Equals(button_cam)) // 카메라 연결/해제 버튼
{
if (!m_isRunning)
{
if (t_cap != null && t_cap.IsAlive)
{
MessageBox.Show("Camera is closing... Wait..", "Error");
return;
}
t_cap = new Thread(new ThreadStart(ThreadFunc));
t_cap.IsBackground = true; // 프로그램 꺼질 때 쓰레드도 같이 꺼짐
m_isRunning = true;
t_cap.Start();
button_cam.Content = "Close";
}
else
{
m_isRunning = false;
image_cam.Source = null;
button_cam.Content = "Open";
}
}
else if (sender.Equals(button_image)) // 이미지 로드 버튼
{
OpenFileDialog openFileDialog = new OpenFileDialog();
openFileDialog.Filter = "PNG files (*.png)|*.png|BMP files (*.bmp)|*.bmp|JPG files (*.jpg)|*.jpg|JPEG files (*.jpeg)|*.jpeg|All files (*.*)|*.*";
if (openFileDialog.ShowDialog() == true)
{
Mat image = Cv2.ImRead(openFileDialog.FileName);
if (!image.Empty()) text_image.Text = "Image: " + openFileDialog.SafeFileName;
else text_image.Text = "Image: " + "No Model";
Run(image);
}
}
else if (sender.Equals(button_model)) // 모델 로드 버튼
{
OpenFileDialog openFileDialog = new OpenFileDialog();
openFileDialog.Filter = "ONNX Weight files (*.onnx)|*.onnx|All files (*.*)|*.*"; // ONNX 파일만
if (openFileDialog.ShowDialog() == true)
{
net = OpenCvSharp.Dnn.CvDnn.ReadNetFromOnnx(openFileDialog.FileName);
if (!net.Empty()) text_model.Text = "Model: " + openFileDialog.SafeFileName;
else text_model.Text = "Model: " + "No Model";
}
}
else if (sender.Equals(check_facedet)) // face detection 체크 박스
{
if (check_facedet.IsChecked == true) b_facedet = true;
else b_facedet = false;
}
}
// Slider 값 변경 이벤트
private void SliderEvent(object sender, RoutedPropertyChangedEventArgs<double> e)
{
if (sender.Equals(slider_face_conf))
{
face_confidence = (float)slider_face_conf.Value / 100.0f;
}
}
ThreadFunc 함수입니다. 카메라를 Open 시킨 후 플래그 값(m_isRunning)이 바뀔 때까지 스레드 풀링(Pooling)합니다. 루프 안에서 카메라로부터 영상을 받아와 추론을 하고 결과를 출력합니다.
private void ThreadFunc() // 카메라를 연결하고 프레임을 읽고 추론까지 진행함
{
m_capture.Open(0, VideoCaptureAPIs.DSHOW);
Mat frame = new Mat();
while (m_isRunning)
{
if (m_capture.IsOpened() == true)
{
m_capture.Read(frame);
if (!frame.Empty())
Run(frame);
Thread.Sleep(10); // prevent for lag
}
else
{
m_isRunning = false;
image_cam.Dispatcher.Invoke(() => { image_cam.Source = null; });
button_cam.Dispatcher.Invoke(() => { button_cam.Content = "Open"; });
}
}
if (m_capture.IsOpened())
m_capture.Release();
}
ImageROI 함수는 face detection을 수행하는지 안하는지 체크하고 해당하는 이미지를 리스트에 담아 리턴해주는 역할을 수행합니다.
private void ImageROI(Mat image, out List<OpenCvSharp.Rect> faces)
{
faces = new List<OpenCvSharp.Rect>();
if (b_facedet == true)
{
FaceCrop(image, out faces);
}
else
{
OpenCvSharp.Rect rt = new OpenCvSharp.Rect(0, 0, image.Width, image.Height);
faces.Add(rt);
}
}
ImageROI 내부에서 사용된 FaceCrop 함수입니다. Face Detection 기법들이 포함되어있습니다. 기본으로 얼굴 인식이 훈련된 SSD Model을 불러오게 합니다. HaarCascade 기법도 코드에 포함되어있지만 실사용하기에 매우 부족한 성능이라 코드 포함만 해뒀고 실제로 사용하진 않았습니다.
// face detection for using ssd (or haarcascade)
private void FaceCrop(Mat image, out List<OpenCvSharp.Rect> list)
{
list = new List<OpenCvSharp.Rect>();
if (true) // SSD Model : Useful
{
OpenCvSharp.Dnn.Net facenet;
// Download: https://github.com/spmallick/learnopencv/blob/master/FaceDetectionComparison/models/deploy.prototxt
var prototext = "deploy.prototxt";
// Download: https://github.com/spmallick/learnopencv/blob/master/FaceDetectionComparison/models/res10_300x300_ssd_iter_140000_fp16.caffemodel
var modelPath = "res10_300x300_ssd_iter_140000_fp16.caffemodel";
facenet = Net.ReadNetFromCaffe(prototext, modelPath);
Mat inputBlob = CvDnn.BlobFromImage(
image, 1, new OpenCvSharp.Size(300, 300), new OpenCvSharp.Scalar(104, 177, 123),
false, false
);
facenet.SetInput(inputBlob, "data");
string[] outputs = facenet.GetUnconnectedOutLayersNames();
Mat outputBlobs = facenet.Forward("detection_out");
Mat ch1Blobs = outputBlobs.Reshape(1, 1);
int rows = outputBlobs.Size(2);
int cols = outputBlobs.Size(3);
long total = outputBlobs.Total();
ch1Blobs.GetArray(out float[] data);
if (data.Length == 1) return;
for (int i = 0; i < rows; i++)
{
float confidence = data[i * cols + 2]; // Access confidence score
// 설정된 confidence 값보다 클 경우만
if (confidence > face_confidence)
{
int x1 = (int)(data[i * cols + 3] * image.Width);
int y1 = (int)(data[i * cols + 4] * image.Height);
int x2 = (int)(data[i * cols + 5] * image.Width);
int y2 = (int)(data[i * cols + 6] * image.Height);
OpenCvSharp.Rect rt = new OpenCvSharp.Rect(x1, y1, x2, y2);
int centerX = (rt.Left + rt.Right) / 2;
int centerY = (rt.Top + rt.Bottom) / 2;
int width = x2 - x1;
int height = y2 - y1;
// 그냥 face recognition 하면, 얼굴이 너무 빡세게 잡혀서.. 가로세로 10% 정도씩 늘려줌.
float face_scale_X = 0.1f;
float face_scale_Y = 0.1f;
if (x1 - (width * face_scale_X) < 0) x1 = 0;
else x1 = x1 - (int)(width * face_scale_X);
if (x2 + (width * face_scale_X) > image.Width) x2 = image.Width;
else x2 = x2 + (int)(width * face_scale_X);
if (y1 - (height * face_scale_Y) < 0) y1 = 0;
else y1 = y1 - (int)(height * face_scale_Y);
if (y2 + (height * face_scale_Y) > image.Height) y2 = image.Height;
else y2 = y2 + (int)(height * face_scale_Y);
OpenCvSharp.Rect item = new OpenCvSharp.Rect(x1, y1, x2 - x1, y2 - y1);
list.Add(item);
}
}
}
if (false) // Cascade Classifier : Useless
{
// Download: https://github.com/mitre/biqt-face/tree/master/config/haarcascades
string filenameFaceCascade = "haarcascade_frontalface_alt2.xml";
CascadeClassifier faceCascade = new CascadeClassifier();
if (!faceCascade.Load(filenameFaceCascade))
{
Console.WriteLine("error");
return;
}
// detect
OpenCvSharp.Rect[] faces = faceCascade.DetectMultiScale(image);
foreach (var item in faces)
{
list.Add(item);
Cv2.Rectangle(image, item, Scalar.Red); // add rectangle to the image
Console.WriteLine("faces : " + item);
}
}
}
NormalizeImage는 이미지 정규화를 수행합니다. 기본적으로 255를 나눠서 0~1의 값으로 Normalize 시킨 다음에, Mean 값 만큼 빼주고 Std 값 만큼 나눠주는 식으로 수행합니다. 허나 이것도 구현만 해두었고 실제로 사용하진 않습니다. ImageNet의 mean std 값으로도 해봤고 제가 직접 구한 트레이닝 데이터셋의 mean std 값으로도 넣어봤지만 안한 상태가 결과로써 가장 유의미했기 때문입니다.
// 정규화 과정
private void NormalizeImage(ref Mat img)
{
img.ConvertTo(img, MatType.CV_32FC3);
Mat[] rgb = img.Split();
// 0.0f~1.0f
rgb[0] = rgb[0].Divide(255.0f); // B
rgb[1] = rgb[1].Divide(255.0f); // G
rgb[2] = rgb[2].Divide(255.0f); // R
if (b_meanstd)
{
// mean
rgb[2] = rgb[2].Subtract(new Scalar(mean[0])); // B
rgb[1] = rgb[1].Subtract(new Scalar(mean[1])); // G
rgb[0] = rgb[0].Subtract(new Scalar(mean[2])); // R
// std
rgb[2] = rgb[2].Divide(std[0]); // B
rgb[1] = rgb[1].Divide(std[1]); // G
rgb[0] = rgb[0].Divide(std[2]); // R
}
Cv2.Merge(rgb, img);
Cv2.Resize(img, img, resz);
}
마지막으로 추론하는 Inference 함수입니다.
// 추론 과정
private void Inference(Mat image, out int label, out double prob)
{
if (net.Empty())
{
MessageBox.Show("No Found Model!");
label = -1; prob = 0;
return;
}
if (image.Empty()) {
label = -1; prob = 0; return;
}
Mat resizedImage = image.Clone();
Mat blob = new Mat();
NormalizeImage(ref resizedImage);
blob = CvDnn.BlobFromImage(resizedImage, 1.0f,
new OpenCvSharp.Size(224, 224), swapRB:true, crop:false);
net.SetInput(blob);
string[] outBlobNames = net.GetUnconnectedOutLayersNames();
Mat[] outputBlobs = outBlobNames.Select(toMat => new Mat()).ToArray();
Mat matprob = net.Forward("output");
// 최대 값의 구하기
double maxVal, minVal;
OpenCvSharp.Point minLoc, maxLoc;
Cv2.MinMaxLoc(matprob, out minVal, out maxVal, out minLoc, out maxLoc);
label = maxLoc.X;
prob = maxVal * 100;
}
이제 하이라이트인 Inference(추론) 함수에 대해서는 자세히 살펴보겠습니다.
1. 이미지를 Normalize 한 후에 BlobFromImage 함수를 통해 적절히 파라미터를 입력하고 OpenCV의 DNN에 사용되는 데이터 형식인 Blob 형태로 만들어줍니다.
(참고1) Blob 형태는 NCHW 포맷으로, N:데이터 개수, C:채널 개수, H:Height, W:Width입니다.
2. 생성된 Blob은 SetInput 함수를 통해 입력으로 넣어줍니다.
3. 다음에 Forward(OutputName)으로 추론을 진행합니다. 여기서 OutputName은 이전 포스팅의 모델 코드에서 SaveToONNX 함수에 output_names으로 설정한 값을 넣으시면 됩니다. 제 포스팅대로 진행했다면 "output"을 넣으시면 됩니다.
# pytorch의 모델을 onnx 포맷으로 저장
def SaveToONNX(model, onnx_save_path):
...
output_names = ['output']
...
# 모델 변환
torch.onnx.export(model, # 실행될 모델
...
output_names = output_names # 모델의 출력값을 가리키는 이름
)
...
4. Forward의 결과로 나온 값을 MinMaxLoc 함수를 이용해 최소, 최대 값을 구하고 위치(여기서는 라벨의 번호)와 값을 Inference 함수의 리턴 값으로 넘겨줍니다.
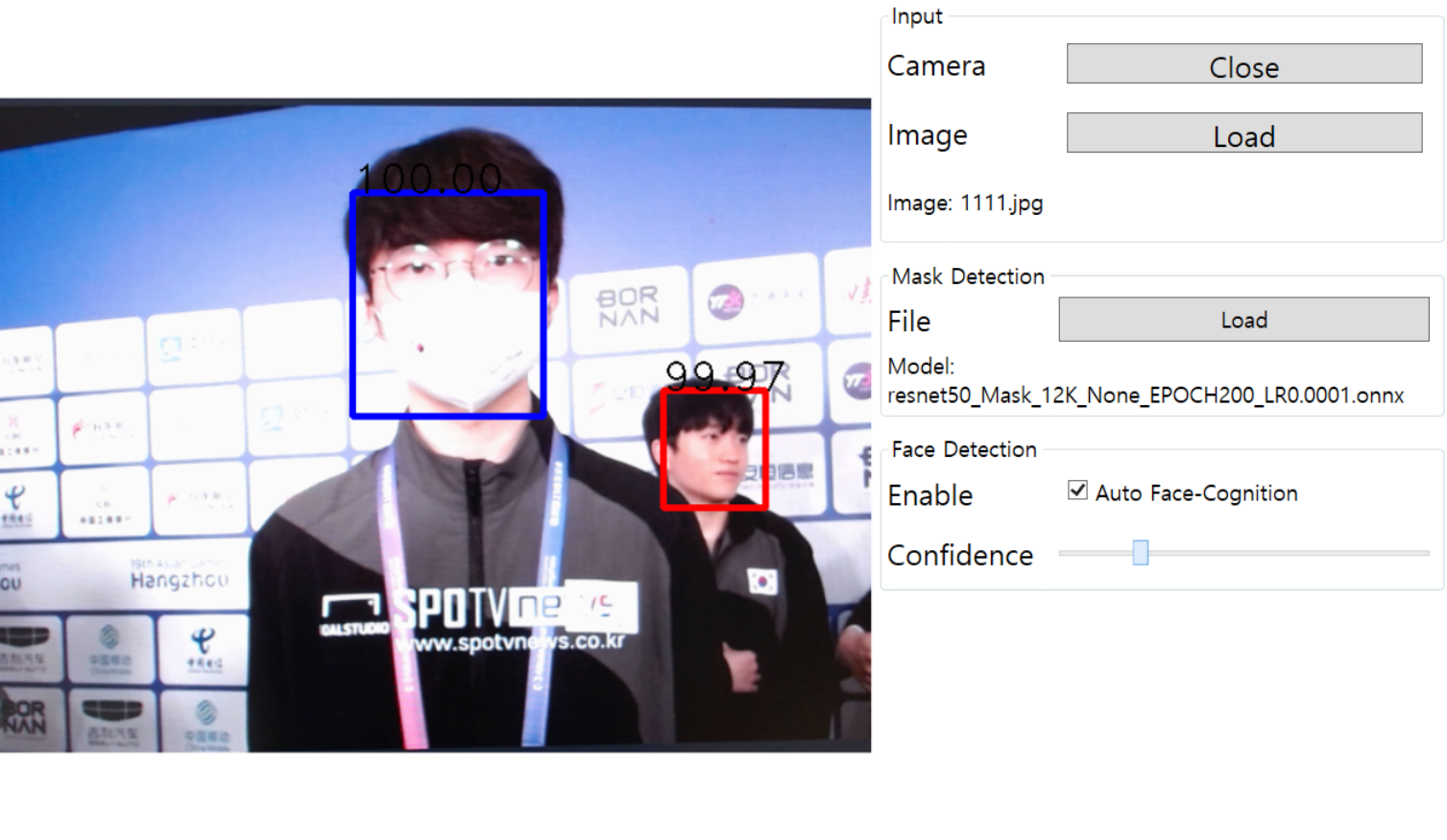
짜잔! 프로그램 완성입니다! Face Detection으로 얼굴의 ROI를 잡아주고 해당 얼굴 위치에 마스크 착용 유무를 체크합니다!
'Deep Learning > 프로젝트' 카테고리의 다른 글
| [2] C# WPF + Pytorch - 마스크 인식 딥러닝 프로젝트: 학습 코드 (1) | 2025.01.06 |
|---|---|
| [1] C# WPF + Pytorch - 마스크 인식 딥러닝 프로젝트: 소개 및 환경 세팅 (1) | 2024.12.31 |