전체 소스 코드
PyroNote/MaskDetection at main · 21june/PyroNote
My DeepLearning Test Repository. Contribute to 21june/PyroNote development by creating an account on GitHub.
github.com
(ResNet 모델 코드에 대한 설명은 나중에 따로 논문 요약하면서 코드에 대해 포스팅을 올려볼 생각이 있어서 이번 프로젝트에서는 패스합니다. 모델쪽은 주석으로 대략 정리는 해두었으니 참고하시면 될 것 같습니다. 해당 모델 코드는 혁펜하임님의 Legend 13 강의의 소스 코드를 참고했습니다.)
임포트 및 디바이스 설정
다음과 같이 임포트를 진행했습니다.
# pytorch
import torch
from torch import nn, optim
from torchvision import datasets, transforms
from torch.utils.data import Dataset, DataLoader, random_split
from torch.optim.lr_scheduler import _LRScheduler
import torchvision.models as models
# matplotlib
import matplotlib.pyplot as plt
# etc
import os
import math
import random
from tqdm import tqdm # 진행도 측정용
import onnx
import onnxruntime
import numpy as np
# GPU가 인식되면 GPU 사용, 아니면 CPU 사용
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(DEVICE)
print(torch.__version__)
상수 값
학습에 사용될 파라미터 값들을 입력합니다. 적절하게 파라미터를 조절해서 학습을 진행하시면 됩니다. 특별하게 해당 상수 값을 사용한 이유는 없고 주로 초기값으로 많이들 사용해서 저도 동일하게 사용해봤습니다.
BATCH_SIZE = 64 # batch size
LR = 1e-4 # learning rate
EPOCH = 200 # input num of epoch
num_classes = 2 # input num of classes
criterion = nn.CrossEntropyLoss() # for Loss
model_type = "resnet18" # select model
dataset = "Mask_12K" # using dataset
dataset_path = f"/mnt/e/Base_Dataset" # dataset path
save_model_path = f"/mnt/e/Results/{model_type}_{dataset}_EPOCH{EPOCH}_LR{LR}.pt" # model path to save
save_onnx_path = f"/mnt/e/Results/{model_type}_{dataset}_EPOCH{EPOCH}_LR{LR}.onnx" # onnx path to save
save_lastepoch_model_path = f"/mnt/e/Results/{model_type}_{dataset}_{mean_std_type}_EPOCH{EPOCH}_LR{LR}_LASTEPOCH.pt" # model path to save
save_lastepoch_onnx_path = f"/mnt/e/Results/{model_type}_{dataset}_{mean_std_type}_EPOCH{EPOCH}_LR{LR}_LASTEPOCH.onnx" # onnx path to save
train_share = 0.8 # percentage of train dataset
valid_share = 0.1 # percentage of val dataset
test_share = 0.1 # # percentage of test dataset(path 관련 값들은 안바꾸시면 오류나니까 꼭 수정하시고 사용해주세요.)
데이터 셋
데이터 셋을 적당히 세팅해줍니다. 먼저 transform을 통해 간단히 전처리를 해줍니다. Resize를 224, 224로 맞춰준 것은 ResNet이 224, 224 사이즈의 입력 이미지를 기준으로 나온 논문이기 때문입니다. 당연히 다른 사이즈를 넣어도 되지만 최적의 학습을 위해서는 가능하면 저 값을 맞춰주는게 좋습니다.
참고로, ToTensor()를 하면 픽셀 별 RGB 값들이 0~1의 값으로 변경됩니다. 따라서 ToTensor() 이후 Normalize()를 해줘야하며 반대로 할 경우 제대로 동작하지 않을 수 있습니다.
Normalize의 값은 학습 데이터(여기서는 이미지 데이터)들의 Mean, Std를 구해서 평균 값을 R,G,B 각각 넣어주시면 됩니다. ImageNet은 ImageNet 데이터셋의 값이며, Mask12K는 제가 직접 구한 Mean, Std 값입니다.
(+추가) 실제로 학습하고 실제 영상으로 테스트해보니 Normalize로 mean, std를 안넣은게 가장 결과가 좋았습니다.
if dataset == "Mask_12K":
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
]
)
if mean_std_type == "Mask12K":
transform = transforms.Compose(
transform.transforms + [transforms.Normalize(mean=[0.5703, 0.4665, 0.4177], std=[0.2429, 0.2231, 0.2191])]
)
elif mean_std_type == "ImageNet":
transform = transforms.Compose(
transform.transforms + [transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]
)
이어서, dataset을 적절한 위치를 지정해 로드한 후 앞서 입력한 share 비율만큼 나눠줍니다. 이후 사용자 정의 함수인 show_random_images를 사용해 랜덤하게 이미지를 로드한 후 라벨 값을 확인합니다. 데이터 라벨링이 적절하게 되어있는지 확인하는 과정이며 각 라벨링이 어떤 번호로 되어있는지 확인하기 위해 사용합니다.
dataset_path = f"/mnt/e/Mask_12K" # 데이터셋 경로
train_DS = datasets.ImageFolder(root=dataset_path, transform=transform)
# Default: train 70%, valid 15%, test 15%
train_size = int(train_share * len(train_DS))
valid_size = int(valid_share * len(train_DS))
test_size = len(train_DS) - train_size - valid_size
train_DS, val_DS, test_DS = random_split(train_DS, [train_size, valid_size, test_size])
train_DL = torch.utils.data.DataLoader(train_DS, batch_size=BATCH_SIZE, shuffle=True)
val_DL = torch.utils.data.DataLoader(val_DS, batch_size=BATCH_SIZE, shuffle=True)
test_DL = torch.utils.data.DataLoader(test_DS, batch_size=BATCH_SIZE, shuffle=True)
train_loader = DataLoader(train_DS, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_DS, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_DS, batch_size=BATCH_SIZE, shuffle=False)
# 적합하게 라벨링 되어있는지 랜덤으로 가져와서 테스트하는 용도
dataloaders = { 'Train': train_DL, 'Valid':val_DL, 'Test': test_DL }
show_random_images(dataloaders, n=10)
라벨 0번이 마스크 착용, 1번이 마스크 미착용이네요. 라벨 값들과 이미지를 비교해보니 적절하게 잘 들어가 있는 모양입니다. 잘 기억해뒀다가 추론 할 때도 사용해봅시다.
모델 설정
이후 모델을 선택합니다. ResNet은 레이어 깊이에 따라 여러 모델이 존재합니다. resnet 뒤에 붙은 숫자는 레이어의 수를 의미하니 높을수록 깊어져 학습이 더욱 정확해지지만 학습이 상당히 느려집니다. 이 프로젝트에선 깊은 단계까진 필요없고 resnet18정도로 진행해보겠습니다. 이후 모델의 형태를 텍스트로 확인합니다.
# 사용할 모델 선택
if model_type == "resnet18":
model = resnet18(num_classes=num_classes).to(DEVICE)
elif model_type == "resnet34":
model = resnet34(num_classes=num_classes).to(DEVICE)
elif model_type == "resnet50":
model = resnet50(num_classes=num_classes).to(DEVICE)
elif model_type == "resnet101":
model = resnet101(num_classes=num_classes).to(DEVICE)
elif model_type == "resnet152":
model = resnet152(num_classes=num_classes).to(DEVICE)
elif model_type == "resnet18_pretrained": # pytorch 모델 사용 + pretrained 사용
model = models.resnet18(pretrained=True).to(DEVICE)
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, num_classes).to(DEVICE)
elif model_type == "resnet50_pretrained": # pytorch 모델 사용 + pretrained 사용
model = models.resnet50(pretrained=True).to(DEVICE)
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, num_classes).to(DEVICE)
print(model) # 모델 구성 확인
x_batch, _ = next(iter(train_DL))
print(model(x_batch.to(DEVICE)).shape)(Output)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(stage1): Sequential(
(0): BasicBlock(
(residual): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(1): BasicBlock(
(residual): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
...
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=2, bias=True)
)
torch.Size([64, 2])마지막 줄의 torch.Size([64, 2])의 경우, train dataloader에서 한 번의 iterator인 이미지 64(=BATCH_SIZE)개 만큼 가져와서 model에 추론한것의 shape를 확인한 것입니다. 64개 이미지 각각의 라벨별(마스크O, 마스크X 2가지 라벨) 확률이 들어가 있습니다.
(예시)
model(x_batch.to(DEVICE))의 [0,0] 값 = 첫 번째 이미지에서 마스크 쓰고 있을 확률
model(x_batch.to(DEVICE))의 [0,1] 값 = 첫 번째 이미지에서 마스크 안 쓰고 있을 확률
학습 및 검증
학습에 앞서 몇 가지 변수를 추가했습니다.
optimizer = optim.Adam(model.parameters(), lr=LR)
# ReduceLROnPlateau # https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.ReduceLROnPlateau.html
# 후에 step에서 넣는 값(여기서는 val_loss)의 변화를 추적하여 LR 값을 조정하는 방식.
# 여기서는 val_loss가 연속적인 EPOCH 10(patience)회 동안 낮아지지(min) 않을 경우,
# 새로운 LR 값을 LR * 0.1(factor)을 계산하여 생성한다. 단, 새로운 LR 값은 0(min_lr)을 넘어야한다.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=1e-4, threshold_mode='rel', min_lr=0, verbose=False)
train_losses = []
val_losses = []
best_val_loss = float('inf')| optimizer | 옵티마이저를 설정합니다. 여기서는 Adam을 사용합니다. |
| scheduler | learing rate 값을 조절할 스케쥴러를 설정합니다. 상황에 따라 LR Scheduler를 안쓰는 경우도 있고 다른 알고리즘을 사용해도 되지만 여러 프로젝트를 봤을 때 ReduceLROnPlateau랑 CosineAnnealing 기법이 자주 사용되는 것 같습니다. |
| train_losses, val_losses | plot에 각 EPOCH 별로 loss 값을 출력하기 위해 사용됩니다. 매 EPOCH마다 값이 저장됩니다. |
| best_val_loss | val_loss가 낮아질 때마다 모델을 저장하기 위해서는 해당 값이 필요합니다. |
이제 본격적으로 학습에 진행합니다.
for ep in range(EPOCH):
model.train() # train mode로 전환
train_loss = 0.0
with tqdm(train_DL) as tepoch: # 진행도 체크용
# Training Loop
for x_batch, y_batch in train_DL:
tepoch.set_description(f"Epoch {ep+1} / {EPOCH}")
x_batch = x_batch.to(DEVICE)
y_batch = y_batch.to(DEVICE)
optimizer.zero_grad() # gradient 누적을 막기 위한 초기화
y_hat = model(x_batch) # inference
loss = criterion(y_hat, y_batch)
loss.backward() # backpropagation
optimizer.step() # weight update
train_loss += loss.item()
train_loss /= len(train_DL)
train_losses.append(train_loss)
# eval mode로 전환
model.eval()
val_loss = 0.0
with torch.no_grad(): # gradient 자동 계산 X / val, test땐 gradient 계산이 필요없으니
for x_batch, y_batch in val_DL:
x_batch = x_batch.to(DEVICE)
y_batch = y_batch.to(DEVICE)
y_hat = model(x_batch) # inference 결과
loss = criterion(y_hat, y_batch) # loss check
val_loss += loss.item()
val_loss /= len(val_DL)
val_losses.append(val_loss)
print(f"Epoch [{ep+1}/{EPOCH}], Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
# LR Scheduler
if scheduler is not None:
# 앞서 확인했듯이 ReduceLROnPlateau는 매 사이클마다 확인하는 메트릭이 필요함. 여기서는 val_loss의 값을 기준으로 한다.
if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(val_loss)
else:
scheduler.step()
# 베스트 모델만 저장함. 여기서 베스트 모델은 val_loss 값이 낮은 것.
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model, save_model_path)
SaveToONNX(model, save_onnx_path)
# 마지막 EPOCH Weight 저장
torch.save(model, save_lastepoch_model_path)
SaveToONNX(model, save_lastepoch_onnx_path, x_batch)코드의 큰 흐름은 다음과 같습니다.
(1) train - mode 변경 (train)
(2) train - dataloader를 통해 이미지 및 라벨 한 묶음(BATCH_SIZE=64) 가져와서 x_batch, y_batch에 넣기
(3) train - x_batch, y_batch로 순전파, 역전파 진행 후 train_loss 체크하고 weight 값 업데이트
(4) val - mode 변경 (eval)
(5) val - dataloader를 통해 이미지 및 라벨 한 묶음(BATCH_SIZE=64) 가져와서 x_batch, y_batch에 넣기
(6) val - x_batch, y_batch로 순전파, 역전파 진행 후 val_loss 체크하기 (train이 아니라서 weight 값 업데이트는 안함)
(7) schedular를 통해 lr(learning rate)값 업데이트 (선택)
(8) ONNX 데이터 저장
(9) 1~8번의 과정을 dataloader 마지막 iteration까지 반복한다.
학습 결과 그래프
다음과 같이 EPOCH에 따른 train_loss, val_loss 값 그래프를 그려보겠습니다.
# EPOCH 별 val, train loss 체크
plt.plot(range(1, EPOCH+1), train_losses, 'b')
plt.plot(range(1, EPOCH+1), val_losses, 'r-')
plt.xlabel('EPOCH')
plt.ylabel('Loss')
plt.title('Train vs. Val Loss')
plt.grid()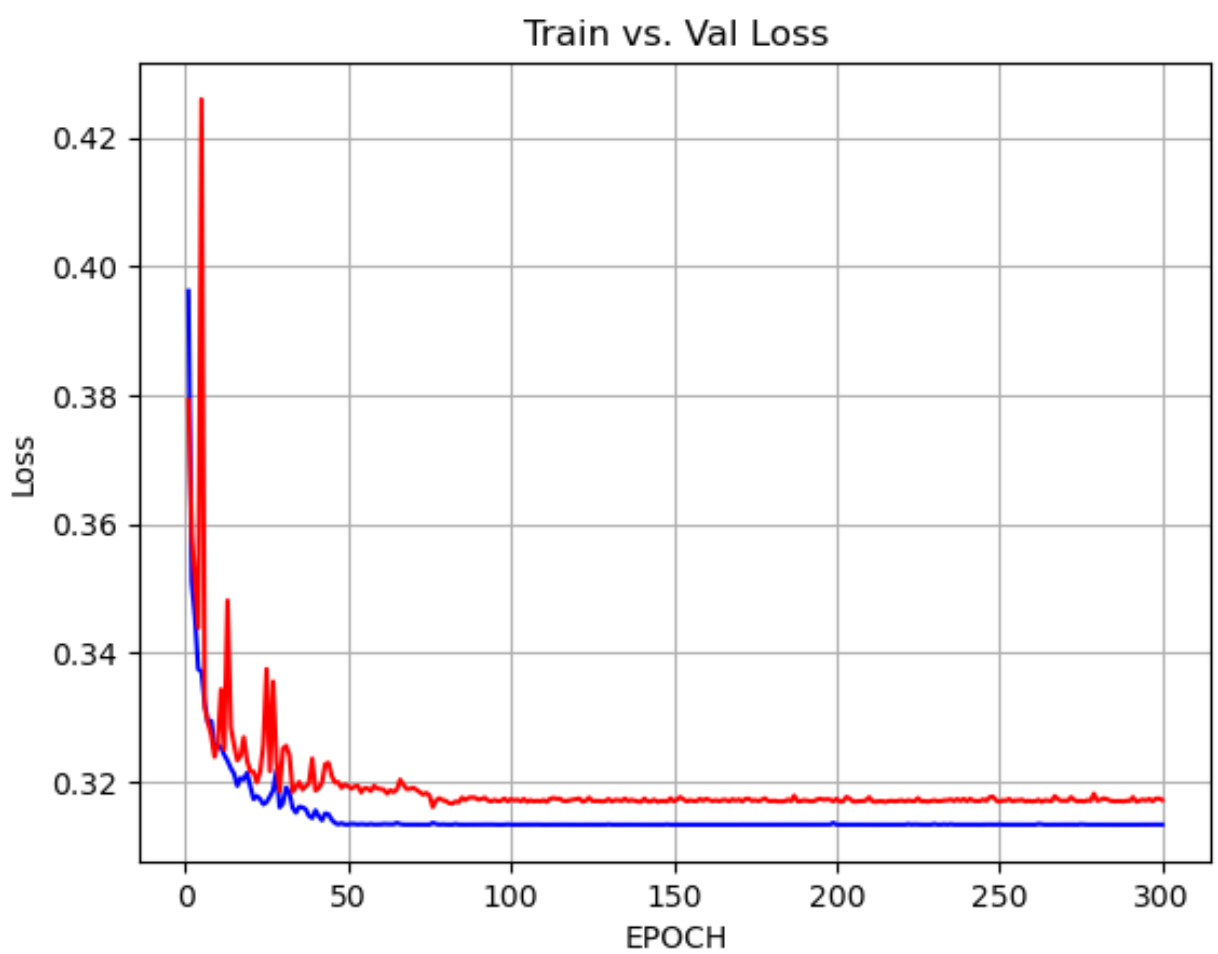
위와 같은 그래프가 나옵니다. 처음에는 많이 요동치다가 EPOCH 80쯤부터 잠잠해집니다. 이 프로젝트는 EPOCH를 100번정도로 해도 충분한 것 같네요.
테스트
테스트는 학습, 검증 과정과 상당히 유사합니다. 다만 테스트는 EPOCH가 1번 뿐이며, weight를 업데이트 해주는 등의 과정을 안해도 된다고 보시면 됩니다. 테스트는 학습한 값을 가지고 추론해서 나온 값을 확인하는 단순한 과정이므로 당연한거겠죠?
model.eval()
test_loss = 0.0
correct = 0
total = 0
# Test Loop
with torch.no_grad():
for x_batch, y_batch in test_loader:
x_batch = x_batch.to(DEVICE)
y_batch = y_batch.to(DEVICE)
y_hat = model(x_batch) # inference
loss = criterion(y_hat, y_batch)
test_loss += loss.item()
_, predicted = torch.max(y_hat, 1)
correct += (predicted == y_batch).sum().item()
total += y_batch.size(0)
accuracy = 100.0 * correct / total
test_loss /= len(test_loader)
print(f"Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%")
(Output)
Test Loss: 0.3155, Accuracy: 99.77%똑같이 loss와 accuracy를 출력하고 테스트가 끝납니다. 정확도 99.77%로 엄청 잘 나왔네요! 결과물 파일도 다음과 같이 잘 나온걸 확인할 수 있습니다. Resnet18은 43MB, Resnet50은 92MB정도 나오네요.

다음 포스팅은 이번 학습의 결과물로 나온 파일(onnx)를 가지고 실제 어플리케이션(C#, WPF)에서 로드 후 추론까지 진행하는 코드를 살펴보겠습니다.
'Deep Learning > 프로젝트' 카테고리의 다른 글
| YOLO Object Detection 모델 커스텀 데이터셋 학습 (교통 표지판) (0) | 2025.05.27 |
|---|---|
| [3] C# WPF + Pytorch - 마스크 인식 딥러닝 프로젝트: GUI 코드 (4) | 2025.01.06 |
| [1] C# WPF + Pytorch - 마스크 인식 딥러닝 프로젝트: 소개 및 환경 세팅 (4) | 2024.12.31 |